プロジェクト概要
実施背景や成果物などの詳細です。
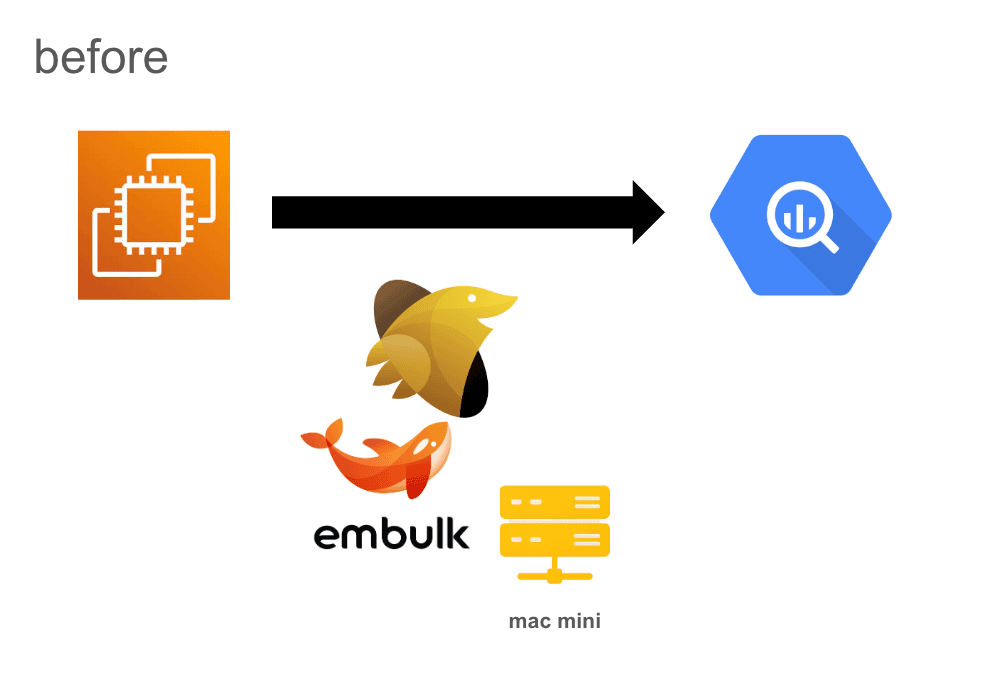
下記のような課題がありました。
1. データの流し込み処理だけオンプレ環境になっている
コードが適切にgit管理されていない
UPSがないため計画停電でサーバーが落ちる
2. データ分析にかける予算を削減したい / 全社意向でawsに移行させたい
3. データの定義が記載されていないため、現場の人が活用できない
定義がどこにもなく、探りながらテーブル定義を探す必要有
しかも定義を知っている人がすでに退職しているため探りながらデータ基盤を探さないといけなく、、、)
そこでデータ基盤を刷新いたしました。
1. データの流し込み処理をクラウド/git管理化
2. awsに統一、S3 + Glue + Athenaを利用して格納コストを下げる
3. Notionとdbt docsでテーブル定義などを管理